DEEP RESEARCH · NVIDIA/GROQ
NVIDIA's Strategic Groq Deal and the Reshaping of AI Inference
A structured analysis of the reported $20 billion deal, LPU determinism, and the AI chip landscape for 2026~2028.
0. Bottom line first
My read is that NVIDIA is trying to extend its training-GPU dominance into inference efficiency. Groq's LPU offered ultra-low latency and deterministic execution, and NVIDIA can use that capability to address inference cost and delay, the weaker side of the GPU stack.
- The source presents the December 24, 2025 NVIDIA-Groq strategic deal as a $20 billion, roughly KRW 28 trillion event.
- Groq was founded in 2016 by Jonathan Ross, a key Google TPU designer, and built the LPU for real-time inference.
- For the next three years, the source frames NVIDIA, Broadcom, and Rebellions as the platform consolidator, custom ASIC partner, and independent inference-chip alternative.
1. Why inference now matters
The first phase of generative AI centered on securing GPUs such as H100 and Blackwell for training. Once models moved into production services, the bottleneck shifted toward inference cost, latency, and power efficiency.
Interpretation: Conversational AI, agentic AI, real-time search, coding, and support services are latency-sensitive and often run at small batch sizes. GPUs are powerful, but not always the most efficient answer for that workload.
2. Groq LPU: deterministic execution and SRAM
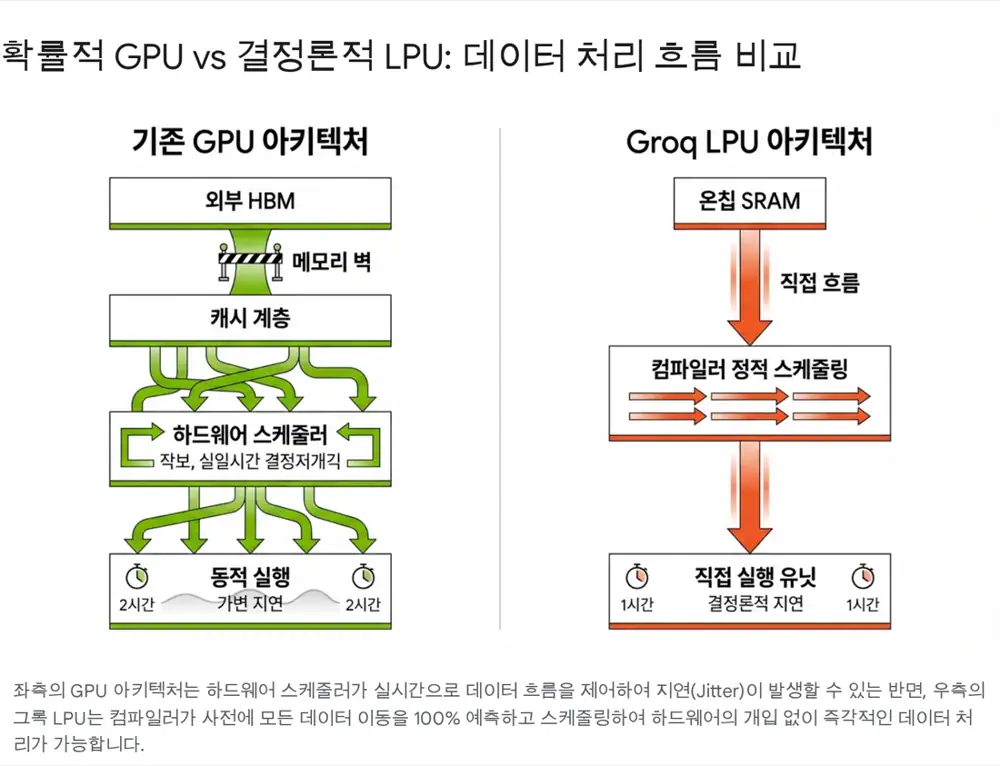
The key idea is to reduce hardware scheduling, cache-control, and branch-prediction logic, while the Groq compiler pre-plans data movement and operation timing at the clock-cycle level.
Official fact: The source says Groq places about 230MB of SRAM on chip and cites more than 80TB/s of internal bandwidth.
Interpretation: SRAM is fast but small. Groq addresses capacity by linking hundreds of chips through RealScale interconnect so the compiler can treat the rack like one large processor.
3. GPU vs TPU vs LPU

| Category | GPU | TPU | LPU |
|---|---|---|---|
| Philosophy | Massive parallelism and generality | Systolic arrays for matrix math | Deterministic execution for low latency |
| Memory | HBM, source cites 80GB for H100 | HBM + ICI | About 230MB on-chip SRAM |
| Strength | CUDA ecosystem and training | Google-scale training efficiency | Ultra-low-latency predictable inference |
| Weakness | Source cites 30~40% utilization at Batch Size=1 | Limited accessibility | Requires rack-scale design for large models |
4. Strategic meaning and macro backdrop
The source frames the deal as a strategic acquisition or technology-licensing combination and as NVIDIA's answer to pressure from Google TPU and independent inference chips. It also says Groq partnered with Aramco in February 2025 for a Middle East deployment of more than 19,000 LPUs, a project worth about $1.5 billion.
Genesis Mission
The source describes Groq as one of 24 key partners in the DOE/OSTP-led AI-for-science infrastructure effort.
Project Prometheus
The $6.2 billion Jeff Bezos-backed physical AI project could become a low-latency chip demand source, according to the source.
Middle East data centers
The Aramco partnership and 19,000+ LPU deployment are presented as major revenue drivers.
5. 2026~2028 picks and risks
NVIDIA
- Groq's SRAM and compiler capabilities could help NVIDIA cover both training and inference.
- Risks include antitrust pressure and faster in-house chip development by large customers.
Broadcom
- Broadcom can benefit from demand by Google, Meta, OpenAI, and others seeking custom AI chips to reduce NVIDIA dependence.
Rebellions
- If Groq moves into NVIDIA's orbit, the market may need another independent high-performance inference-chip vendor.
- The source mentions Samsung Foundry 4nm/2nm, HBM integration, a 2026 Rebel-Quad production plan, and Saudi Aramco investment.
My conclusion is simple: the AI chip war is shifting from “who can build the biggest chip” to “who can control computation most efficiently.” That means CUDA, compilers, memory hierarchy, and rack-scale interconnect all matter together.
Sources
- Source 1: https://m.blog.naver.com/PostView.naver?blogId=star_of_self&logNo=224123717510
- Source 2: https://techstrong.ai/articles/nvidia-strikes-20-billion-licensing-deal-for-groq-ai-technology/
- Source 3: https://www.varindia.com/news/nvidia-20b-groq-deal-signals-new-phase-of-ai-chip-consolidation
- Source 4: https://www.webpronews.com/the-deterministic-bet-how-groqs-lpu-is-rewriting-the-rules-of-ai-inference-speed/
- Source 5: https://medium.com/the-low-end-disruptor/groqs-deterministic-architecture-is-rewriting-the-physics-of-ai-inference-bb132675dce4
- Source 6: https://www.youtube.com/watch?v=xBMRL_7msjY
- Source 7: https://www.weforum.org/people/jonathan-ross/
- Source 8: https://www.reddit.com/r/NVDA_Stock/comments/1apeo2w/deeper_dive_into_interview_with_jonathan_ross_ceo/
- Source 9: https://medium.com/@salihturkoglu/processing-units-is-all-you-need-e0dcd58e78cf
- Source 10: https://drive.google.com/open?id=13Uw85NwEXsVowA7EM3_1xhVbTTAGzWY9
- Source 11: https://www.reddit.com/r/deeplearning/comments/1dhy93q/why_are_gpus_more_preferable_than_tpus_for_dl/
- Source 12: https://blog.startupstash.com/groq-vs-nvidia-the-real-world-strategy-behind-beating-a-2-trillion-giant-58099cafb602
- Source 13: https://www.investing.com/news/stock-market-news/nvidia-to-acquire-groq-for-20-billion-in-its-largest-deal-ever-cnbc-reports-4422745
- Source 14: https://www.tomshardware.com/tech-industry/artificial-intelligence/nvidia-buys-ai-chip-startup-groqs-assets-for-usd20-billion-in-the-companys-biggest-deal-ever-transaction-includes-acquihires-of-key-groq-employees-including-ceo
- Source 15: https://groq.com/newsroom/groq-and-nvidia-enter-non-exclusive-inference-technology-licensing-agreement-to-accelerate-ai-inference-at-global-scale
- Source 16: https://www.streetinsider.com/Investing/Breaking+down+Nvidia%E2%80%99s+unusual+%2420+billion+deal+with+Groq/25779684.html
- Source 17: https://the-decoder.com/nvidias-20-billion-groq-deal-is-really-about-blocking-googles-tpu-momentum/
- Source 18: https://www.thestreet.com/investing/nvidia-makes-its-biggest-purchase-ever
- Source 19: https://www.reddit.com/r/LocalLLaMA/comments/1puyq9r/exclusive_nvidia_buying_ai_chip_startup_groqs/
- Source 20: https://sacra.com/c/groq/
- Source 21: https://www.pminsights.com/companies/groq
- Source 22: https://medium.com/tdk-ventures/an-insider-investor-view-on-groq-d9bbd6c1a291
- Source 23: https://www.reddit.com/r/mlscaling/comments/1el4knb/groq_2023_sales_as_low_as_34_million_and_a_net/
- Source 24: https://tracxn.com/d/companies/groq/__pMJjkNzO3GELYaHvYyAD0pQB4BYTFTHh4Klu4dAJvoU/funding-and-investors
- Source 25: https://www.energy.gov/genesis-mission
- Source 26: https://www.hpcwire.com/2025/12/01/genesis-mission-americas-strategic-shift-in-ai-for-science/
- Source 27: https://www.energy.gov/articles/energy-department-announces-collaboration-agreements-24-organizations-advance-genesis
- Source 28: https://groq.com/newsroom/groq-partners-with-us-department-of-energy-to-advance-ai-inference-and-next-generation-computing-infrastructure
- Source 29: https://timesofindia.indiatimes.com/technology/tech-news/jeff-bezos-to-lead-6-2-billion-ai-startup-project-prometheus-understanding-the-project-and-could-this-outpace-chatgpt/articleshow/125409255.cms
- Source 30: https://www.vktr.com/ai-market/inside-project-prometheus/
- Source 31: https://www.nasdaq.com/articles/prediction-these-3-artificial-intelligence-ai-stocks-will-be-big-winners-again-2026
- Source 32: https://www.investopedia.com/ai-stocks-could-stay-the-place-to-be-next-year-here-are-two-banks-top-chip-picks-11873732
- Source 33: https://www.investing.com/analysis/amd-vs-nvidia-vs-broadcom-3-very-different-ai-plays-200671935
- Source 34: https://koreatechdesk.com/rebellions-arm-first-asia-investment-korea-ai-chips-global
- Source 35: https://www.siliconrepublic.com/start-ups/rebellions-raises-250m-arm-samsung-ai-chip-inference
- Source 36: https://www.fwdstart.me/p/rebellions-raises-250m-at-1-4b-valuation-expands-ai-chip-push-into-saudi-arabia